Analysis of Wikipedia’s Network Structure Using Web Scraping
Contributors
Blake Whiting, and Ben Mercier
Contents
ABSTRACT
Wikipedia is a constantly evolving archive of knowledge and information, and its network structure captures the complex relationships between articles, editors, and other endpoints. Our objective is to analyze the network data of Wikipedia to gain insights into the structure of the online encyclopedia. More specifically, determine what are the most connected articles on Wikipedia, and how they relate to each other. We will collect network data from Wikipedia using web scraping and data-cleaning techniques. We will then analyze the network structure of Wikipedia using graph theory and network science tools, such as degree distributions, clustering coefficients, and centrality measures. By analyzing this network data, we can understand how information flows and how communities form and evolve on Wikipedia.
Introduction
A wiki is a software that enables individuals to contribute, modify, edit, and delete parts of a website [1]. The first wiki was created in 1994 by Ward Cunningham, going by the name WikiWikiWeb [1]. Since then, wikis have proliferated the Internet to become part of most people's everyday lives. However, one wiki stands above them all, Wikipedia [1]. Since its foundation in 2001, Wikipedia has set the standard for online wikis [2]. Wikipedia's model has lowered the barrier to entry for people wishing to participate in its online community, garnering it much popularity in the early 2000s [2]. Wikipedia is now available in several languages, including English, French, Italian, Japanese, etc., with the English Wikipedia's number of active editors peaking at around 51,000 in 2007 [2].
During our Social, Info, and Tech Networks course, we have had the opportunity to learn about social networks and the trends and behaviors that govern their structure. Wikipedia is one of the world's largest multilingual and collaborative free-knowledge repositories [2], with a constantly evolving archive of knowledge and information whose network structure captures the complex relationships between articles, editors, and other endpoints.
Our objective is to analyze the network data of Wikipedia to gain insights into the structure of the online encyclopedia. More specifically, determine what are the most connected articles on Wikipedia, and how they relate to each other. We will collect network data from Wikipedia using web scraping and data-cleaning techniques. We will then analyze the network structure of Wikipedia using graph theory and network science tools, such as degree distributions, clustering coefficients, and centrality measures. By analyzing this network data, we hope to understand how information flows and how communities form and evolve on Wikipedia.
Related Works & Background
To gain insight into Wikipedia's network structure, trends, and community culture, we reviewed previous academic papers that focused on Wikipedia specifically or network structures in general. These papers provided us with guidance on how to execute our project and what we could expect to learn about the network structure of Wikipedia.
One of the most relevant papers we reviewed by Suchecki et al. discusses the evolution of Wikipedia's category structure [1]. This paper set out to investigate how the clustering of articles matches the direct link network between articles, and how it changes over time [1]. This paper provided us with an excellent history of Wikipedia's development and how the platform has evolved since its inception. Suchecki et al.'s aim was to examine the Wikipedia category system, which differs from a traditional hierarchical category system as it has no defined root or hierarchy [1]. At the beginning of Wikipedia's life, there was no dedicated system for organizing articles [1]. The Wikipedia category system, implemented in 2004, made it possible to assign articles to categories and link these categories to each other [1]. However, to analyze the structure of the category system more clearly, Suchecki et al. hierarchized it to have a definitive root and top-level categories [1]. After analyzing the category system, Suchecki et al. determined that Wikipedia's category structure is rather stable, meaning the average number of links per page has not changed much over the years [1]. More interestingly for us, Suchecki et al. captured the number of articles per category, showing that categories like ambiguous, politics, entertainment, music, and arts contain the most articles. We are interested to see by crawling the articles on Wikipedia if the most connected articles on Wikipedia, or nodes with the highest degrees, fall into the categories Suchecki et al. determined to have the most articles. Finding this correlation would help to substantiate that both of our research's findings are accurate.
Another paper we reviewed by Marc Miquel-Ribe, Cristian Consonni, and David Laniado studied the trends in Wikipedia's community growth and decline [2]. Similar to the previous paper, this study offered us a comprehensive account of the developmental journey of Wikipedia and its evolution since its beginning. Miquel-Ribe et al. remarked that Wikipedia demonstrated that an online community could come together to collaborate on a peer-driven project [2]. However, they were curious about the health of Wikipedia's community and whether it could sustain itself. To determine if Wikipedia's community was healthy, Miquel-Ribe et al. assessed its growth, stagnation, and decline patterns using monthly active editor reports for various language editions of Wikipedia [2]. They found that communities, although experiencing occasional stagnation or decline, are more robust than expected [2]. Considering human knowledge is ever-expanding, there will always be information to add to Wikipedia, ensuring its long-term survival. Overall, this paper aided our understanding of our research topic by providing insights into the history, function, and organization of Wikipedia.
A similar paper we reviewed delved into the norms that have developed in Wikipedia's community over a fifteen-year period [3]. Heaberlin and DeDeo state that the editors who contribute to articles on Wikipedia rely on social norms to standardize and regulate editing decisions [3]. Heaberlin and DeDeo's work was relevant to our studies because they used a similar data collection technique. To assemble data on network norms on Wikipedia, Heaberlin and DeDeo parsed the raw HTML within the namespace reserved for policies, guidelines, processes, and discussions to form a directed, unweighted network of norms [3]. In summary, Heaberlin and DeDeo concluded that Wikipedia's user base experienced exponential growth until 2007 when population growth began to stall [3]. Furthermore, they determined that norms are crucial to cultural evolution and gain meaning from the relationships that connect them [3]. Altogether, this paper offered insights into the application of web scraping to collect and analyze data from Wikipedia for research purposes. Additionally, it gave us a greater understanding of using directed, unweighted graphs to classify Wikipedia's network structure.
A paper by Foster et al. further elaborated on the nature of networks and how edge detection can have profound effects on assortativity [4]. Assortivity refers to the tendency of high-degree nodes to connect to other high-degree nodes [4]. We have previously discussed assortativity in class, but this paper offered an alternative perspective in the context of Wikipedia. Foster et al.'s goal was to demonstrate that simply labeling networks as strictly assortative or disassortative misses fundamental features of said networks [4]. They go further by showing that many networks can display a mixture of both tendencies. Foster et al.'s results revealed that Wikipedia is assortative, indicating that pages with a high in-degree link to pages with a high out-degree more frequently than expected [4]. In simpler terms, authoritative pages link to useful pages more often than previously thought [4]. These findings offered us the opportunity to determine if our results, obtained from analyzing the structure of Wikipedia, confirm whether its structure is assortative or disassortative.
The last paper we reviewed was by Yasseri et al., which examined the dynamics of collaborative conflicts in Wikipedia [5]. As we have discussed previously, Wikipedia allows people to modify, edit, and delete articles on the site. However, collaborations on articles are not always peaceful [5]. Luckily, the Wikipedia community has developed a system to help resolve conflicts that arise during collaborations on Wikipedia articles [5]. Yasseri et al. studied the interactions between users when these conflicts occur and determined that disputes between editors can consume a considerable amount of editorial resources [5]. However, these disputes do eventually resolve themselves or fizzle out. Although this paper did provide a substantial contribution to our research, it again offers insights into Wikipedia's structure and community dynamics.
Methods
To gather data on the network structure of Wikipedia, we used a slightly modified version of the crawler code one of our members built for the first assignment in the course. We found that it was a highly scalable solution that would collect the required data to help us in our findings. Our crawler begins by importing the necessary libraries. The urllib3 library is used to make HTTP requests to web pages. The BeautifulSoup library is used to parse HTML documents and extract information from them. The networkx library is used to represent the web pages and their links as a graph. Finally, the urllib.parse library is used to parse URLs.
The maximum number of pages that will be crawled is set to 80,000. This number limits the amount of data that our crawler will collect to a manageable size. Our crawler ended up getting 6,712 pages with the first version of the code, and 6,481 pages with the second version. These versions will be explained further in this report. Our crawler then defines a Queue class. A queue is a data structure that stores items in the order in which they were added. In our crawler, the queue is used to store the URLs that will be crawled. The Queue class has several methods for adding, removing, and querying items in the queue. The push() method adds an item to the end of the queue, while the pop() method removes the item from the front of the queue. The peek() method returns the item at the front of the queue without removing it. The isempty() method checks whether the queue is empty. The size() method returns the number of items in the queue. Finally, the contains() method checks whether an item is in the queue.
Our crawler then sets the root URL to be crawled, the queue, and the graph. The root URL is set to "https://en.wikipedia.org/". The processing queue is created using the Queue class. The processed set is used to store the URLs that have already been crawled. The graph is created using the networkx DiGraph class, which represents a directed graph. The root node is added to the graph, and the root URL is added to the processing queue.
The main loop of our crawler crawls the website. The loop runs as long as the processing queue is not empty and the number of processed pages is less than the maximum number of pages. The loop has three main parts: processing the current URL, extracting links from the current page, and adding the links to the processing queue. The first part of the loop gets the current URL from the processing queue using the pop() method. It then prints the number of pages processed so far and the current URL. The number of processed pages is obtained from the length of the processed set. The second part of the loop extracts links from the current page. It uses the BeautifulSoup library to parse the HTML of the current page and extract all of the links on the page. It then checks each link to see if it is a valid URL and whether it has already been processed or is already in the processing queue. There are two versions of the code that we used for this final project. In the first version, every URL containing the root domain was considered valid. The second version filters out the wiki article for Wikipedia, which produced several thousand links in the first version of our code. If the link is valid and has not been processed or added to the queue, it is added to the processing queue, and an edge is added to the graph from the current URL to the new URL. The third part of the loop adds the new URLs to the processing queue. If the link is a relative link, it is joined with the current URL to form an absolute URL. This ensures that the link is valid and can be visited by our crawler. The link is then added to the processing queue using the push() method. The loop also contains error handling code, handled with a try/except function. If an error occurs while processing a URL, the error is caught, and our crawler continues to crawl the website. If the user interrupts the program by pressing CTRL-C, our crawler stops and prints an error message. This step is required for the next part of the code to function if the page limit is not reached.
Once our web crawler has finished crawling the website, it exports the graph to a file in GEXF format using the networkx library's write_gexf function. GEXF (Graph Exchange XML Format) is a widely used format for representing graph data, and it allows a graph to be easily visualized and analyzed using various tools and software. The file name of the exported graph is dynamically generated based on the number of pages processed. This is a useful feature because it allows you to easily keep track of different crawls and their corresponding graphs. For example, if you were to run the crawler again at a later time, you could name the file something like "Wikipedia_fp_1000.gexf" to indicate that it's the second crawl of the website, and it has processed 1000 pages.
One of the issues that we ran into with our crawler was that the server running it had a memory overflow that was not caught by the code. The issue was found when stopping the program after 18,000 links crawled. This problem that we discovered is the reason that our crawler did not ever reach 80,000 pages crawled. We discovered that since the code was storing the file data in a variable until the loop either ended or our crawler was interrupted, the data would not write correctly to the file. The virtual machine running on the server indicated that the machine was utilizing the entirety of the system’s memory, which further explained the speed issues of the code. We ran our crawler one more time, but this time, boosted the memory allocated to the virtual machine to 64 Gigabytes, up from the 4 Gigabytes previously. With the increased memory allocation, our crawler was run again to address the memory overflow issue. The higher memory capacity allowed the code to function more efficiently and prevented the VM from using all the allocated memory. This resulted in smoother program execution and more reliable file writing operations.
The next problem we encountered was that Gephi does not have the capability to process a dataset this large. With approximately 6,500 pages crawled, there were almost 1.3 million nodes and edges in the graph. After boosting the system resources available to the computer running Gephi from 32 Gigabytes to 250 Gigabytes, Gephi was still unable to keep up with the size of the dataset and continued to crash. We decided we needed a smaller set of data points to be able to complete this project in a timely manner, so we ran the crawler one more time, but this time, we stopped it at 100 pages crawled. This gave us just over 60,000 nodes and edges on the pages.
Results
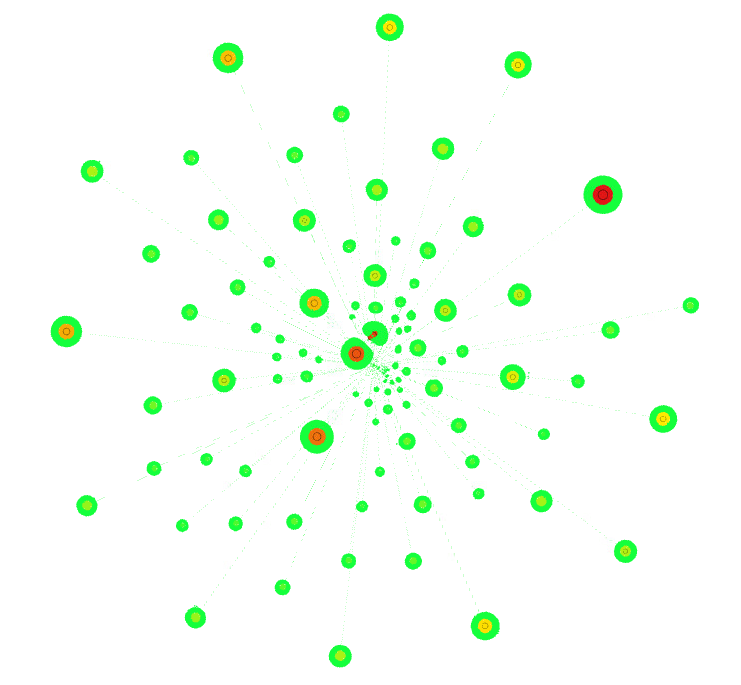
This section will show some of the many statistics available from the data we collected to provide a clearer understanding of Wikipedia’s structure. After some minor setbacks with Gephi being unable to process the volume of data we collected, we managed to get a community visulization of the first 100 pages of Wikipedia (Figure 1).
- Number of nodes: 60143
- Number of edges: 60239
- Edge Density: 0.000
- Average degree: 1.002
- Average clustering coefficient: 0.000
- Nodes in strongly connected component (SCC): 60143
- Nodes in weakly connected component (WCC): 1
- Average path length: 1.4995
- Modularity: 0.976
- Modularity with resolution: 0.976
- Number of Communities: 88
- Network Diameter: 2
Figure 1 shows the communities of the first 100 pages of Wikipedia crawled, using the ForeAtlas 2 community visualization algorithm.
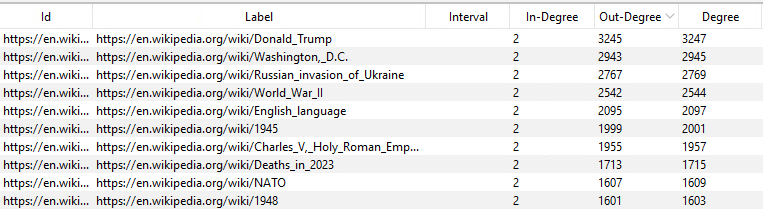
In Figure 2, we see the top ten nodes in the network, sorted by the highest degree. They all have an in-degree of 2, meaning they only receive inbound connections from 2 other nodes. However, these nodes have an astonishingly high number of connected outbound nodes. The top three articles are Donald Trump, Washington D.C., and the Russian Invasion of Ukraine. These are all closely related to current major events happening around the world, and most have to do with some of the worst of human activity. The presence of Donald Trump at the very top illustrates the significant media attention he receives. His reach goes far beyond just his fan-base, and he has been a widespread topic on the Internet due to the fact that he is the first former US president to be indicted and arraigned. Figure 3 shows the Donald Trump article, and the cluster of neighbor nodes surrounding it. Washington D.C at the very top is likely significant due to the city having a large impact on global politics. The Russian Invasion of Ukraine is a tragic event that has been a major global concern. The conflict between Russia and Ukraine has caused widespread violence, displacement of people, and geopolitical tensions. The high connectivity of this topic in the network may indicate the extensive discussions, debates, and news coverage surrounding the ongoing conflict and its repercussions on regional and global stability. Collectively, the top three nodes in the network show the intersection of politics, current events, and human behavior, with a focus on controversial and often negative aspects of human activity. The high connectivity of these nodes suggests the significant attention and engagement with these topics in the network, reflecting the importance of these events and their impact on the global landscape.

When taking a closer look at the Wikipedia homepage, https://en.wikipedia.org/, we can see that it has a degree of 112. It is also clear that this node is a central node in the network since its in-degree is 0. We can further analyze the network by looking at the nodes that this connects to. We see that the neighbor nodes are all within the top high-degree nodes, which corroborate the results of Foster et al. [4], showing that Wikipedia is in fact assortative, meaning that higher-degree nodes will tend to connect to other high-degree nodes. We can also deduce that the structure and connectivity patterns of Wikipedia depend heavily on the degree of the node. This could have impacts on the flow of information on Wikipedia, as well as navigation and the dynamics of how articles will gain popularity in the network.
Conclusion
In conclusion, we have investigated the network structure and dynamics of Wikipedia to reveal interesting behaviors and relationships that occur between articles. Our results illustrate that the most connected articles coincide with popular media topics and major world events. This outcome makes sense as popular topics garner the most attention from editors and viewers alike. Furthermore, our results support the findings of Suchecki et al. [1] in that the categories with the most articles consist of politics and entertainment. Similarly, our results confirm Foster et al.'s [4] findings that the structure of Wikipedia is assortative, meaning that pages with a high in-degree link to pages with a high out-degree.
Wikipedia is an extremely complex platform whose network structure captures the complex relationships between the collection and documentation of knowledge, global trends, cultures, and social dynamics. Our findings provided insights into these relationships and the overall network structure of Wikipedia. By analyzing this network data, we have gained a better understanding of how information diffuses through society and how communities form and evolve on Wikipedia.
Acknowledgements
We would like to acknowledge Professor Amirali for his hard work and dedication in making a course about networks, nodes, and centrality interesting and fun. I have taken cool courses that were bad because of how they were taught, and boring courses that were made even worse because of how they were taught. Professor Amirali knew this was the final stretch of our University career and he put in the effort to make it worthwhile for everyone who attended his class. Give this man a raise!
References
[1] Krzsztof Suchecki and Alkim A. Salah and Cheng Gao and Andrea Scharnhorst. 2012. Evolution of Wikipedia's Category Structure. arXiv. DOI:https://doi.org/10.48550/arXiv.1203.0788
[2] Marc Miquel-Ribe and Cristian Consonni and David Laniado. 2022. Community Vital Signs: Measuring Wikipedia Communities’ Sustainable Growth and Renewal. Sustainability. 14(8), 4705-. DOI:https://doi.org/10.3390/su14084705
[3] Bradi Heaberlin and Simon DeDeo. 2016. The Evolution of Wikipedia’s Norm Network. Future Internet. 8(4), 14-35. DOI:https://doi.org/10.3390/fi8020014
[4] Jacob G. Foster and David V. Foster and Peter Grassberger and Maya Paczuski. 2010. Edge direction and the structure of networks. Proceedings of the National Academy of Sciences. 107(24), 10815-10820. DOI:https://doi-org.uproxy.library.dc-uoit.ca/10.1073/pnas.0912671107
[5] Taha Yasseri and Robert Sumi and Andras Rung and Andras Kornai and Janos Kertesz. 2012. Dynamics of conflicts in Wikipedia. PloS One. 7(6), e38869–e38869. DOIhttps://doi.org/10.1371/journal.pone.0038869